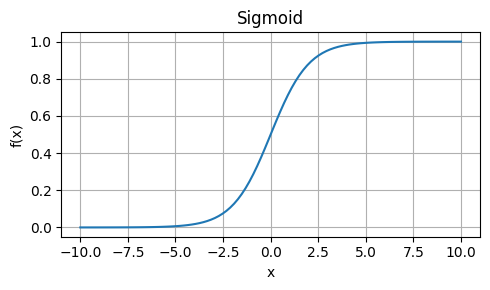
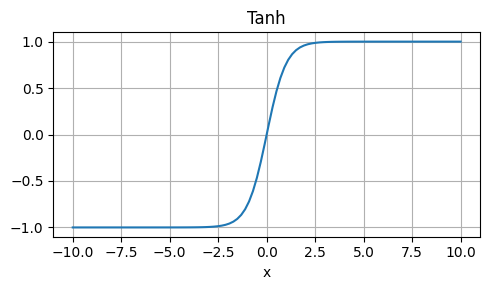
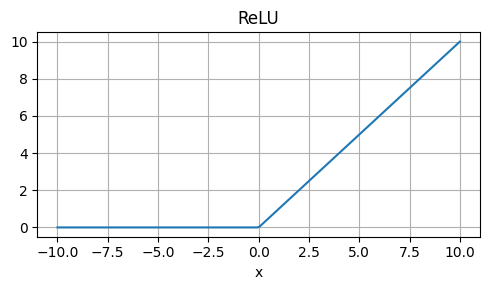
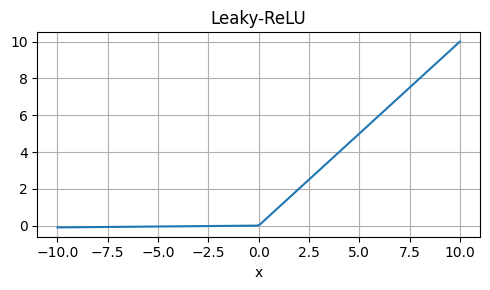
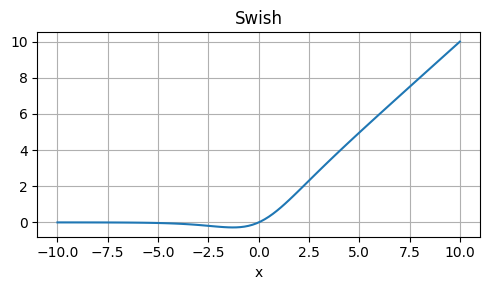
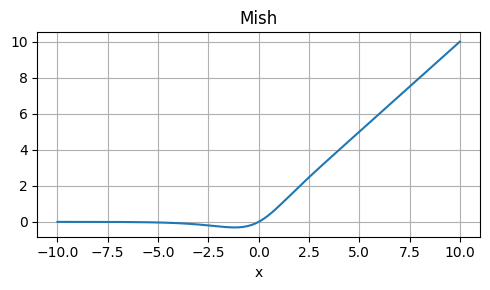
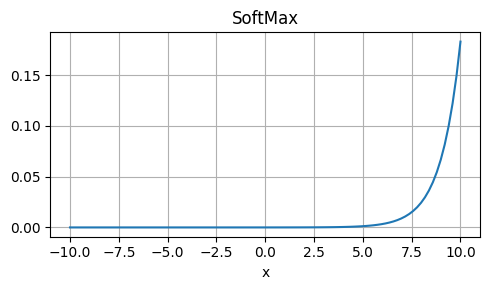
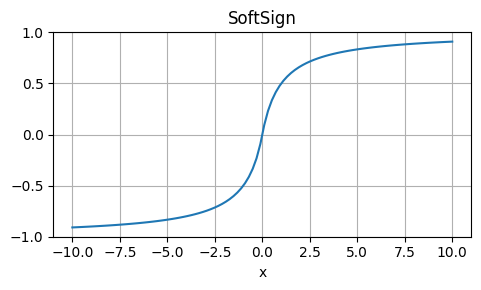
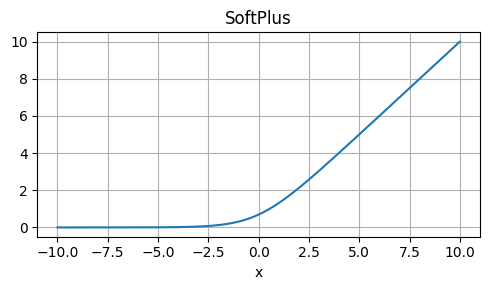
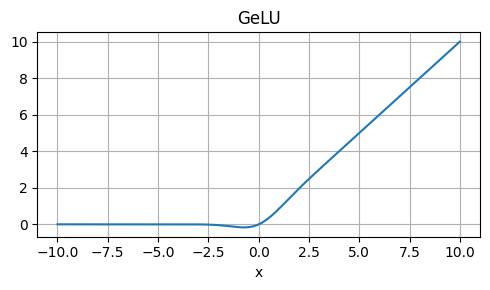
Weaknesses: Approximation, not exactly equal to GELU.
Usage: Alternative to GELU, especially when computational efficiency is crucial.
SELU (Scaled Exponential Linear Unit)
\[
f(x) = \lambda
\begin{cases}
x & x > 0 \\
\alpha e^x - \alpha & x \leq 0
\end{cases}
\]
Strengths: Self-normalizing, non-saturating, and computationally efficient.
Weaknesses: Requires careful initialization and α tuning.
Usage: Alternative to ReLU, especially in deep neural networks.
I will incorporate a timeline diagram using Mermaid to visually represent the key milestones in the history of AI. Here’s the updated plan with the inclusion of the timeline, and I’ll proceed to create the detailed content for the slideshow afterward.
Detailed Slideshow Plan
Introduction to AI
Define AI and its importance in modern technology.
Early Concepts and Theoretical Foundations
Discuss the philosophical roots and ideas like the Turing Test.
The Birth of AI: The Dartmouth Conference
Details on the 1956 Dartmouth workshop and its contributions.
Early Successes and Challenges
Initial achievements and the subsequent AI winters.
Rise of Machine Learning
Shift from symbolic AI to machine learning paradigms.
AI Goes Mainstream: 2000s to Present
Highlight key advancements and the proliferation of AI in various sectors.
Ethical Considerations and Future Outlook
Explore the ethical dilemmas and future possibilities.
Conclusion
Summarize the evolution and impact of AI.
Timeline Diagrams
Key moments from the early theoretical concepts to the latest developments in AI will be represented in a Mermaid timeline for visual impact.
Now, I’ll gather the necessary information to fill in these sections and create the Mermaid timeline. Once the content is prepared, I’ll compile it into a format suitable for a slideshow. Let’s start with the first section, “Introduction to AI,” and proceed from there. Here’s the detailed content for the introduction:
Slide 1: Introduction to Artificial Intelligence
Title: Introduction to Artificial Intelligence
Content:
Definition: Artificial Intelligence (AI) involves creating computer systems that can perform tasks that typically require human intelligence. These tasks include decision-making, object detection, speech recognition, and language translation.
Impact: AI transforms industries including healthcare, automotive, finance, and entertainment by automating processes and analyzing large amounts of data with speed and accuracy beyond human capability.
Following this, I’ll move on to the historical aspects and then integrate the timeline. Would you like to add any specific details or case studies to the introduction or other sections?